Developing Amazon Recommendations
By Harrison Li, Thomas Jiang, Masahiro Kusunoki, Daniel Chen
CS 109a Fall 2016
The Amazon Fine Foods Dataset, collected and distributed by the Stanford Network Analysis Project, contains nearly 600,000 Amazon reviews of over 70,000 food and food-related products by over 250,000 users. With this data, we set out to develop a system for predicting future ratings based on a combination of product features and user characteristics. If successful, such a system could be used as an accurate recommendation system.
1. Duplicates
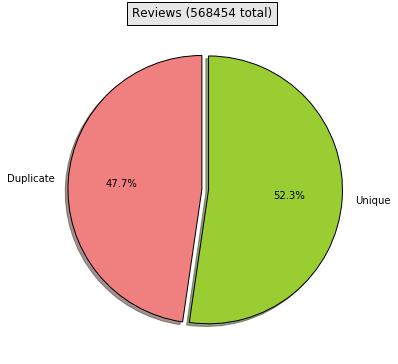
While exploring reviews, we found that several reviews had identical text, scores, user IDs, and timestamps on similar products. This does not seem to suggest a human user, and we hypothesize that these reviewers were left by bots. Including these bots would improve our RMSE (as bots are extremely easy to predict since they continually give identical scores), but for the sake of applicability to human users, we decided to filter out all such reviews, eliminating almost half of all reviews.
2. Number of Reviews by Reviewer
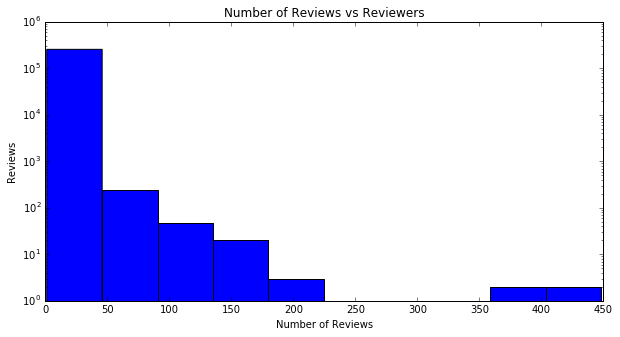
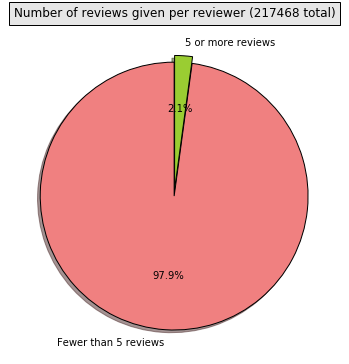
This compares the number of active users, which we define to be users with 5 or more ratings, to the number of inactive users. Inactive users do not have enough ratings for us to accurately judge their product preferences, and therefore our model also removes them when training on our dataset.
3. Number of Reviews by Product
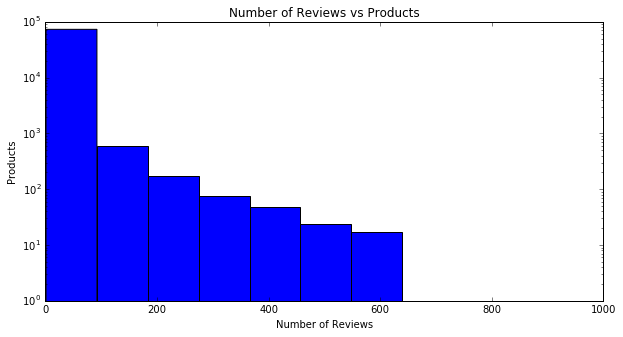
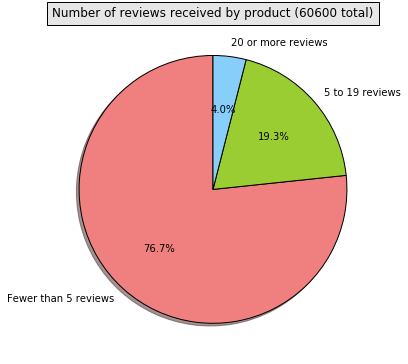
Compounding the sparsity of user ratings, each product also generally has very few ratings. With so few reviews, it's difficult to accurately judge product similarity using just the Fine Food Dataset, motivating us to use the Amazon API to provide additional product features.
4. Helpfulness Skew
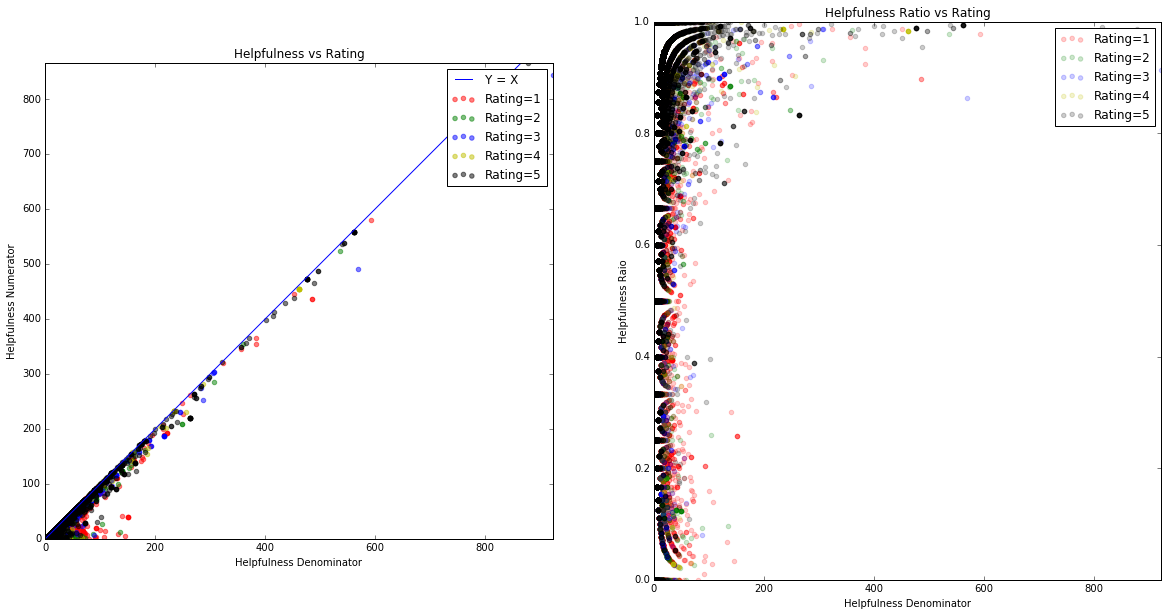
The data provides both helpfulness numerator and denominator. The ratio of the two gives the percent of readers who find each review to be helpful. It's clear that once again, most reviews have very few helpfulness ratings. A rating of 1 out of 1 or 0 out of 1 is not dramatically significant, so when using helpfulness as a proxy for estimating review quality, we assigned a 1, 1 beta prior.
5. Score Skew
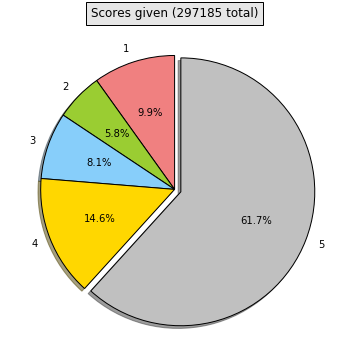
Interestingly, a large majority (63.9%) of the ratings given by users across all products are 5 out of 5, while negative ratings (defined as 3 stars or less) constitute only 22% of all ratings. We did not correct for this phenomenon since we treat the scores as quantitative values instead of categorical, but it is reflected by predicted values also yielding a high average.
6. Time Drift
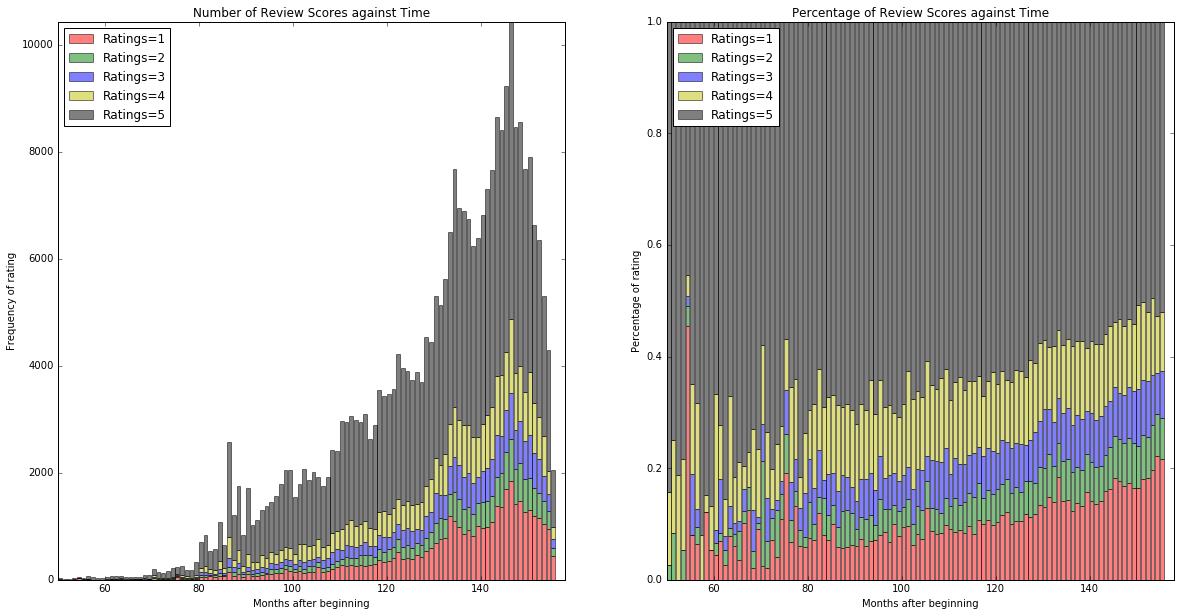
Scores seem to improve over time throughout the dataset. We do not yet have a robust explanation of this phenomenon, but it could potentially be accounted for by a more complex model.
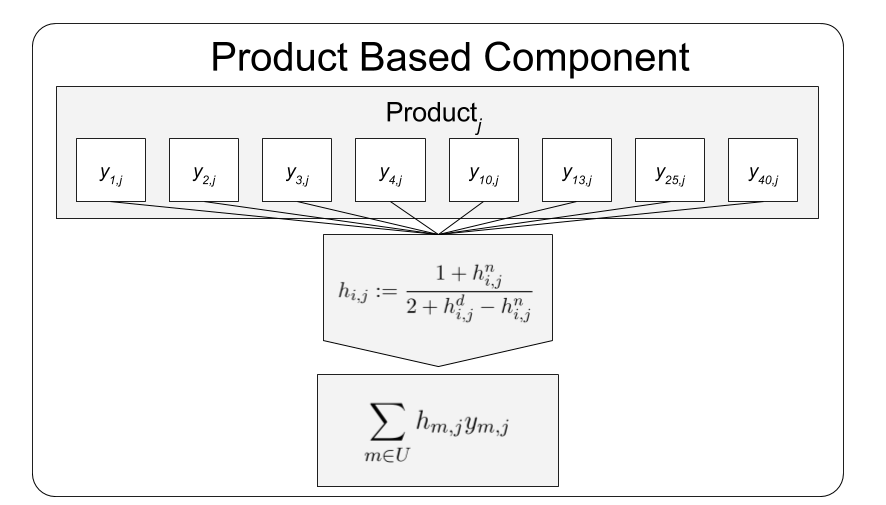
The product-based component is a weighted average of all ratings of that product in the training set, where each rating is weighed by the estimated proportion of users who rated user i’s rating on product j as helpful. This expression is derived from placing an uninformative Uniform (i.e. Beta(1,1)) prior on the helpfulness and taking the posterior mean (PM) estimate after updating the prior with the helpfulness numerator and denominator.
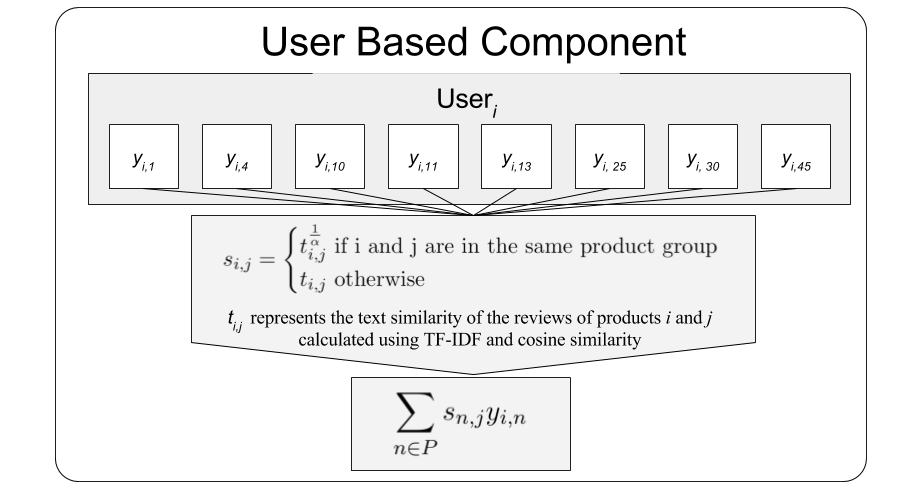
The user-based component is a weighted average of all of the ratings given by a particular user, where a similarity score between 0 and 1 for products n and j, represents the text similarity of the aggregated reviews of products n and j calculated using a TF-IDF vectorizer and cosine similarity. Due to computational limitations we only computed similarity scores for the 10,000 most reviewed products in the training set.
Product group is a categorical designation assigned by Amazon to each product (e.g. “grocery”, “pet foods”). The parameter α controls how much the similarity score for products in the same product group is inflated towards 1. Note that if α = 1, then product similarity reduces to text similarity in all cases.

Our final model is the sum of the product-based and user-based components with relative weights assigned.
Tuning
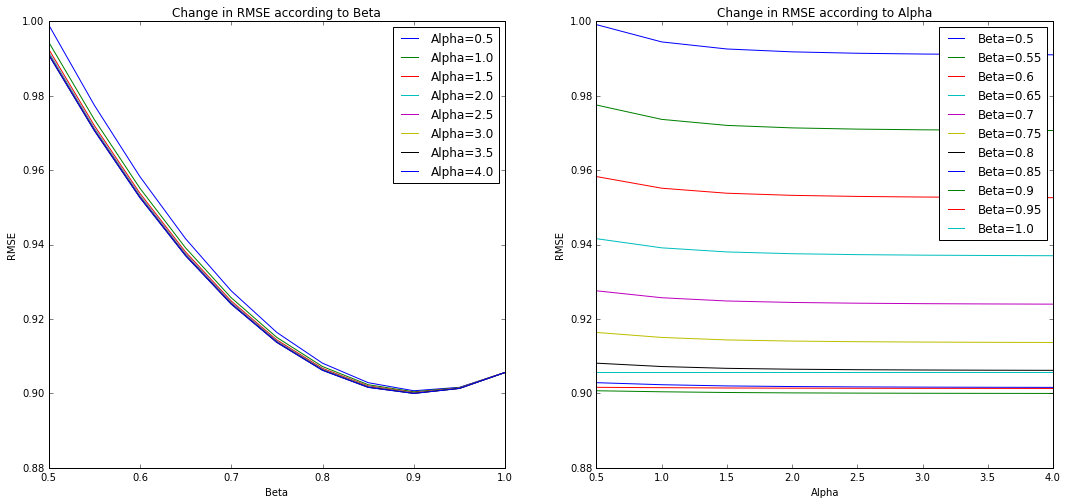
We tune the α and β parameters of the model by using KFold Validation (K=5). Plotting the RMSE scores, we see that this is more sensitive to changes in β, while α seems to have a small effect. We choose the optimal scores with α = 1 and β = 0.9
Improvement over Baseline
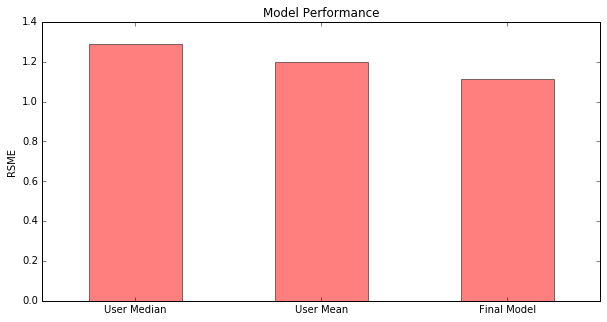
As shown above, our final model manages to beat both of our baseline models by customizing our predictions based on a combination of user preferences for each product, as well as the inherent quality of the products being reviewed.